






 BTC/HKD+0.36%
BTC/HKD+0.36% ETH/HKD+0.75%
ETH/HKD+0.75% LTC/HKD+0.48%
LTC/HKD+0.48% DOT/HKD+0.04%
DOT/HKD+0.04% ADA/HKD+0.42%
ADA/HKD+0.42% SOL/HKD+0.26%
SOL/HKD+0.26% XRP/HKD-0.03%
XRP/HKD-0.03% DOGE/US+0.86%
DOGE/US+0.86%1.走近自然語言理解
文本是一種極其重要的數據類型,下面介紹文本數據中有哪些研究問題和挖掘價值。
1.1概念
在處理數據時經常會接觸到文本,如電影簡介、新聞報道等,以及互聯網上每天大量積累的用戶產生內容,如新浪微博、用戶評論等,因此文本是一種十分常見和重要的數據類型。這些文本大多以自然語言的形式存在,即通過人類語言組織和產生,廣泛應用于我們的日常對話、辦公寫作、閱讀瀏覽等行為中。自然語言處理希望讓機器能夠像人一樣去理解以人類自然語言為載體的文本所包含的信息,并完成一些語言領域的特定任務。
1.2內容
語言是人類智慧長期沉淀的成果,對于看似簡單的文本,從詞匯級別、語法級別、語義級別、應用級別等不同角度出發,都包含大量研究問題和工作內容。
中文NLP中最基礎的一塊內容便是中文分詞。英文等外文語言的單詞之間以空格分開,因此顯式提供了詞和詞之間的邊界。而中文僅使用標點符號進行斷句,字和字之間彼此相連,例如“上海自來水來自海上”。雖然類似N-grams等語言模型并不需要進行中文分詞,但畢竟中文的基本語義單元是詞而不是字,所以在大多數應用場景下,為了正確理解一句話包含的語義,進行準確的中文分詞仍是必不可少的預處理步驟。
詞性標注是指在中文分詞的基礎上,結合上下文對分好的每個詞標注最合適的詞性。常見的詞性有名詞、動詞、形容詞、副詞等,同一詞語在不同的語境下可以表現為不同的詞性,進而在語句中充當不同的語義角色。因此,詞性標注主要是依據詞本身的詞性分布,以及上下文的實際語境來判斷的。
命名實體識別是指識別出語句中的人名、地名、機構名、數字、日期、貨幣、地址等以名稱為標識的實體,大多屬于實詞。而關系抽取則是指完成命名實體識別之后,抽取實體之間存在的關系。例如,“喬布斯出任蘋果公司CEO”,其中喬布斯和蘋果公司分別屬于人名和機構名,而CEO則是兩個命名實體之間的關系。
關鍵詞提取是指從大量文本中提取出最為核心、最具有代表性的關鍵詞。常用的實現算法有TF-IDF和TextRank兩種,在提取之前需要對給定文本進行中文分詞并移除停用詞,即例如,“你”“我”“著”“了”等十分常用但不包含具體語義的詞。TF-IDF選出那些一般并不常用,但是在給定文本中頻繁出現的詞作為關鍵詞;而TextRank則基于詞之間的上下文關系構建共現網絡,將處于網絡核心位置的詞作為關鍵詞。
敦煌飛天壁畫數字藏品將于文化和自然遺產日推出:金色財經消息,靈境·人民藝術館與敦煌工美文化創意有限責任公司、上海藝述事文化傳媒有限公司聯合推出“天歌神韻 神化輕舉”敦煌飛天壁畫數字藏品。該數字藏品將于6月11日0時開啟預售,6月13日10時正式發放。
此次“天歌神韻 神化輕舉”敦煌飛天壁畫數字藏品一共精選了4幅作品,分別是《反彈琵琶伎樂天》《起舞飛天》《散花飛天》壁畫修復版和再創作版《寰球共此仙樂:反彈琵琶伎樂天》(動畫)。其中《反彈琵琶伎樂天》《起舞飛天》《散花飛天》3款為普通款,每款各發行3000份,每份定價118元。(人民網)[2022/6/10 4:16:25]
信息抽取是從非結構化文本中抽取出有意義或者感興趣的字段。例如,對于一篇法律判決文書,從中提取出原告、被告、案件類型、判決結果等信息字段,從而將非結構化文本轉化為結構化數據,便于信息管理和數據分析。目前大多數信息抽取都是通過人工制定規則,使用整理好的模式去目標文本中匹配出相應的字段,或者使用半監督學習,結合人工標注樣本和機器學習模型,在不斷的迭代和反饋中提高信息抽取的準確率。
依存分析主要包括句法依存分析和語義依存分析,其過程都是將原始語句解析為依存樹,樹中的每個節點都代表一個詞,節點之間的連接則反應了詞之間的句法關系或語義關系。通過依存分析,原本以順序排列的詞語之間產生了更加復雜和層次化的關系,便于機器更好地理解語句的語法和語義,從而能夠為后續自然語言處理任務帶來幫助。
詞嵌入是指將詞映射成低維、實值、稠密的詞向量,從而賦予詞語更加豐富的語義涵義,同時更加適合作為機器學習等模型的輸入。詞嵌入的概念非常有用,在自然語言處理任務中應用也十分廣泛。
1.3應用
如果以上內容是從理論角度出發探討NLP涉及的內容,那么從實際應用角度出發,NLP又可以用來實現哪些任務呢?
篇章理解是指對于給定的文章集合,通過處理后能夠把握文章的主要內容并完成一些分類任務,如對文章進行主題分類。篇章理解的實現大多基于有監督學習,即提供標注好的訓練集和待測試的測試集,基于訓練集得到一個能夠準確提取信息、全面把握內容的分類模型,從而應用于測試集的分類任務。
文本摘要是指對于給定的大量文本,提取出核心思想和主要內容,快速生成篇幅更小、便于閱讀和理解的摘要。文本摘要主要分為提取式和生成式兩種,前者從原始文本中直接提取出已有的代表性語句,經過處理和組合后輸出為摘要,后者在理解和融合原始文本的基礎上,自動生成原始文本中沒有的語句并組合為摘要。相較而言,生成式比抽取式更加困難,而人類的習慣也是先閱讀并理解,選出重要的語句,再用自己的語言進行復述、總結和融合。
中國工程院院士:區塊鏈等為構建自然資源調查監測體系提供技術支撐:中國工程院院士、自然資源部國家基礎地理信息中心教授陳軍表示,近年來,大數據、人工智能、5G、區塊鏈、知識圖譜、空間信息等高新技術的迅猛發展和交叉融合,為構建自然資源調查監測體系提供了必要的技術支撐和保障條件。(光明日報)[2020/9/16]
情感分析是指根據語句中蘊含的情感成分判斷整個語句表達的情感傾向,例如,判斷用戶評論是否為積極或消極。情感分析的實現可以是簡單地使用一些情感詞典,對語句中出現的情感詞進行加權組合,從而輸出整個語句的情感得分,也可以使用有監督學習,基于人工標注數據訓練情感分類或回歸模型。
知識圖譜是一種表示知識的方法,使用節點表示實體,使用有向邊表示實體之間的關系,實體和邊都可以具備豐富的屬性,從而將海量知識表示成一個龐大的網絡。知識圖譜模擬了人腦管理和檢索知識的過程,當我們看到喬布斯和蘋果公司這兩個實體時,會很自然地聯想兩者之間的關系。如果能夠將某一領域涉及的知識都以知識圖譜的形式進行整理和組織,那么對于領域知識的管理、推理和檢索等都能起到很大的便利。
文本翻譯是一項十分常用的NLP應用,大家都或多或少使用過Google翻譯等工具將文本從一種語言翻譯成另一種語言。從本質上來看,文本翻譯是一種序列到序列的映射,其實現大多是基于人工標注數據集,即大量源語言文本以及對應的目標語言文本,使用循環神經網絡等深度學習網絡訓練映射模型。當然,不能簡單地將源語言文本中的每個字翻譯成目標語言并直接拼接,而是需要結合兩種語言的語法特點以及具體的上下文語境進行調整,而這也正是文本翻譯面臨的最大困難和挑戰。
問答系統是對傳統搜索引擎的一種改進。傳統搜索引擎接受用戶的關鍵詞作為輸入,以列表形式輸出按相關性遞減排序的搜索結果,用戶仍然需要依次瀏覽,直到找到最符合自己要求的內容。問答系統則直接根據用戶問題返回最準確的答案,其實現涉及NLP的諸多領域,例如,對用戶輸入內容進行理解和處理、以龐大的知識圖譜作為知識存儲、快速高效的知識檢索和推理技術等。
聊天機器人很早便得到了應用,完成一些自動信息采集和回復的功能,但那時的聊天機器人主要基于關鍵詞和模板等人工制定規則,智能程度不高。近年來隨著深度學習等相關技術的發展,以及海量聊天語料的積累,聊天機器人逐漸可以接受任意文本輸入并輸出較為合理的回復。從本質上來看,聊天機器人也屬于序列到序列的映射,但其涉及對用戶輸入文本的理解、知識圖譜、文本生成等多個領域,并且需要解決多輪對話一致性等挑戰。智能聊天機器人主要包括日常調侃的聊天機器人,如微軟小冰等,以及垂直領域的功能機器人,如法律、購車、醫療等領域的專業咨詢機器人。它們作為用戶需求的萬能入口,吸引了大量研究機構和創業公司的密切關注。
聲音 | 以太坊聯合創始人:加密貨幣是貨幣的自然進化形式:據CCN消息,以太坊聯合創始人Joseph Lubin在其發表的文章中表示,“加密貨幣在很多方面都是先前代表制度的自然演變,盡管這種制度有利于國家認可的權力。”[2018/9/27]
2.使用jieba分詞處理中文
我們對NLP是什么和做什么,以及和NLP領域相關的內容和應用有了大致的概覽,現在通過Python中的jieba來部分實現中文分詞。
2.1jieba中文分詞
中文分詞是中文NLP的第一步,一個優秀的分詞系統取決于足夠的語料和完善的模型,很多機構和公司也都會開發和維護自己的分詞系統。這里推薦的是一款完全開源、簡單易用的分詞工具,jieba中文分詞。官網是里面提供了詳細的說明文檔。雖然jieba分詞的性能并不是最優秀的,但它開源免費、使用簡單、功能豐富,并且支持多種編程語言實現。
以下使用Python中的jieba分詞完成一些基礎的NLP任務,如果對jieba分詞感興趣,希望了解更多內容,可以參考官方使用文檔。
首先沒有jieba分詞的話需要安裝,使用pip即可安裝。
pipinstalljieba
2.2中文分詞
中文分詞的模型實現主要分為兩大類:基于規則和基于統計。
基于規則是指根據一個已有的詞典,采用前向最大匹配、后向最大匹配、雙向最大匹配等人工設定的規則來進行分詞。例如對于“上海自來水來自海上”這句話,使用前向最大匹配,即從前向后掃描,使分出來的詞存在于詞典中并且盡可能長,則可以得到“上海/自來水/來自/海上”。這類方法思想簡單且易于實現,對數據量的要求也不高。當然,分詞使用的規則可以設計得更復雜,從而使分詞效果更理想。但是由于中文博大精深、語法千變萬化,很難設計足夠全面而且通用的規則,并且具體的上下文語境、詞語之間的搭配組合也都會影響到最終的分詞結果,這些挑戰都使得基于規則的分詞模型并不能很好地滿足需求。
基于統計是從大量人工標注語料中總結詞的概率分布以及詞之間的常用搭配,使用有監督學習訓練分詞模型。對于“上海自來水來自海上”這句話,一個最簡單的統計分詞想法是,嘗試所有可能的分詞方案,因為任何兩個字之間,要么需要切分,要么無需切分。對于全部可能的分詞方案,根據語料統計每種方案出現的概率,然后保留概率最大的一種。很顯然,“上海/自來水/來自/海上”的出現概率比“上海自/來水/來自/海上”更高,因為“上海”和“自來水”在標注語料中出現的次數比“上海自”和“來水”更多。
聲音 | 曹寅:吳忌寒成為礦霸是商業競爭的自然選擇:據報道,能源區塊鏈實驗室創始合伙人曹寅認為,吳忌寒成為礦霸是必然的結果,只要這個位置有人,就有會礦霸,這是商業競爭的自然選擇。他初衷肯定不是要成為礦霸,礦霸的責任大得一塌糊涂。數字貨幣這個行業很多人早就實現了財富自由,現在還留在這個行業里面的人都是想做事的人,都是有理想的人。[2018/8/5]
其他常用的基于統計的分詞模型還有HMM和CRF等,以及將中文分詞視為序列標注問題,進而使用有監督學習、深度神經網絡等模型進行中文分詞。
jieba分詞結合了基于規則和基于統計兩類方法。首先基于前綴詞典進行詞圖掃描,前綴詞典是指詞典中的詞按照前綴包含的順序排列,例如詞典中出現了“上”,之后以“上”開頭的詞都會出現在這一塊,例如“上海”,進而會出現“上海市”,從而形成一種層級包含結構。如果將詞看作節點,詞和詞之間的分詞符看作邊,那么一種分詞方案則對應從第一個字到最后一個字的一條分詞路徑。因此,基于前綴詞典可以快速構建包含全部可能分詞結果的有向無環圖,這個圖中包含多條分詞路徑,有向是指全部的路徑都始于第一個字、止于最后一個字,無環是指節點之間不構成閉環。基于標注語料,使用動態規劃的方法可以找出最大概率路徑,并將其作為最終的分詞結果。
jieba提供了3種分詞模式。
·精確模式:試圖將句子最精確地切開,適合文本分析。·全模式:把句子中所有可以成詞的詞語都掃描出來,速度非常快,但是不能解決歧義。
·搜索引擎模式:在精確模式的基礎上,對長詞再次切分,提高召回率,適合用于搜索引擎分詞。
以下代碼使用jieba實現中文分詞,使用jieba.cut()函數并傳入待分詞的文本字符串即可。使用cut_all參數控制選擇使用全模式還是精確模式,默認為精確模式。如果需要使用搜索引擎模式,使用jieba.cut_for_search()函數即可。運行以下代碼之后,jieba首先會加載自帶的前綴詞典,然后完成相應的分詞任務。
importjieba
seg_list=jieba.cut("我來到清華大學",cut_all=True)
Billions項目組即使用一個拼接符將一個列表拼成字符串
print("/".join(seg_list))Billions項目組精確模式
世界自然基金會(WWF)使用區塊鏈消除金槍魚產業的非法捕撈:WWF已經開始使用區塊鏈技術來消滅金槍魚行業的非法捕魚活動。據該組織宣布,分布式賬本的透明特性將阻止在太平洋島嶼上的非法購買金槍魚和其他無管制的捕魚活動。消費者只需通過手機APP掃描金槍魚包裝上的二維碼,就能看到這條魚被捕獲的時間、地點以及捕魚船等相關信息。[2018/1/30]
seg_list=jieba.cut("他來到了網易杭研大廈")Billions項目組搜索引擎模式
print("/".join(seg_list))
2.3關鍵詞提取
jieba實現了TF-IDF和TextRank這兩種關鍵詞提取算法,直接調用即可。當然,提取關鍵詞的前提是中文分詞,所以這里也會使用到jieba自帶的前綴詞典和IDF權重詞典。


對于提取的關鍵詞以及權重,將每個關鍵詞的權重作為文字大小,便可以進行字符云可視化。
2.4詞性標注
jieba在進行中文分詞的同時,還可以完成詞性標注任務。根據分詞結果中每個詞的詞性,可以初步實現命名實體識別,即將標注為nr的詞視為人名,將標注為ns的詞視為地名等。所有標點符號都會被標注為x,因此可以根據這個方法去除分詞結果中的標點符號。

3.詞嵌入的概念和實現
詞嵌入是一項非常重要且應用廣泛的技術,可以將文本和詞語轉換為機器能夠接受的數值向量,這里詳細討論其概念和實現。
3.1語言的表示
如何向計算機解釋一個詞語的意思?或者說如何表示一個詞語才能恰當地體現出其包含的語義?看到“蘋果”這個詞時,我們會聯想起可以吃的蘋果這一水果,還會聯想起喬布斯創建的蘋果公司,因此一個詞可以包含多重語義。如果讓計算機分析“蘋果”和“梨子”兩個詞之間的相關性,通過字符串匹配只能得到完全不相等的結論,但是我們知道它們都屬于水果,因此詞語所蘊含的語義實際上非常復雜,無法通過簡單的字符串表示。
語言的表示主要有兩種:符號主義和分布式表示。
符號主義
符號主義中典型的代表是Bagofwords,即詞袋模型。如果將語料詞典中的每個詞都看作一個袋子,那么一句話無非是選擇一些袋子,然后將出現的詞丟入相應的袋子。用數學的語言來說,假設詞典中一共有N個詞,就可以用N個N維向量來表示每個詞。以下是用Python描述的一個簡單例子,這里的詞典中只有5個詞:蘋果、梨子、香蕉、和、好吃,分別用一個五維向量表示,僅對應的維度上為1,其他維度都為0。基于詞袋模型可以方便地用一個N維向量表示任何一句話,每個維度的值即對應的詞出現的次數。

詞袋模型雖然簡單,但其缺點也十分顯著。主要有以下幾點。
·當詞典中詞的數量增大時,向量的維度將隨之增大。雖然常用的漢字只有幾千個,但是依然會給計算帶來很大的不便。
·無論是詞還是句子的表示,向量都過于稀疏,除了少數維度之外的大多數維度都為0。
·每個詞對應的向量在空間上都兩兩正交,任意一對向量之間的內積等數值特征都為0,無法表達詞語之間的語義關聯和差異。
·句子的向量表示丟失了詞序特征,即“我很不高興”和“不我很高興”對應的向量相同,而這顯然是不符合語義的。
分布式表示
分布式表示中典型的代表是WordEmbedding,即詞嵌入,使用低維、稠密、實值的詞向量來表示每一個詞,從而賦予詞語豐富的語義含義,并使得計算詞語相關度成為可能。以最簡單的情況為例,如果使用二維向量來表示詞語,那么可以將每個詞看作平面上的一個點,點的位置即橫縱坐標由對應的二維向量確定,可以是任意且連續的。如果希望點的位置中蘊含詞的語義,那么平面上位置相鄰的點應當具有相關或相似的語義。用數學的語言來說,兩個詞具有語義相關或相似,則它們對應的詞向量之間距離相近,度量向量之間的距離可以使用經典的歐拉距離和余弦相似度等。
詞嵌入可以將詞典中的每個詞映射成對應的詞向量,一個好的詞嵌入模型應當滿足以下兩方面要求。
·相關:語義相關或相似的詞語,它們對應的詞向量之間距離相近,例如“蘋果”和“梨子”的詞向量距離相近。
·類比:具有類比關系的4個詞語,例如,男人對于女人,類比國王對于王后,滿足男人-女人=國王-王后,即保持詞向量之間的關聯類比,其中的減號表示兩個詞向量之間求差。
這樣一來,通過詞嵌入模型得到的詞向量中既包含了詞本身的語義,又蘊含了詞之間的關聯,同時具備低維、稠密、實值等優點,可以直接輸入計算機并進行后續分析。但詞典中的詞如此之多,詞本身的語義便十分豐富,詞之間的關聯則更為復雜,所以相對于詞袋模型,訓練一個足夠好的詞向量模型更加困難。
3.2訓練詞向量
詞向量的訓練主要是基于無監督學習,從大量文本語料中學習出每個詞的最佳詞向量,如維基百科、大量新聞報道等。訓練的核心思想是,語義相關或相似的詞語,大多具有相似的上下文,即它們經常在相似的語境中出現,例如,“蘋果”和“梨子”的上下文中可能都會出現類似“吃”“水果”等詞語,可以使用“開心”的語境一般也能使用“高興”。
詞嵌入模型中的典型代表是Word2Vec,模型實現原理可以參考Mikolov的兩篇文章,,主要包括CBOW和Skip-Gram兩個模型,前者根據上下文預測對應的當前詞語,后者根據當前詞語預測相應的上下文。如果希望進一步深入理解詞嵌入模型訓練的原理和細節,可以仔細研讀以上兩篇文章。如果僅需要應用詞嵌入模型,則直接了解如何用代碼實現即可。
3.3代碼實現
gensim是一款開源的Python工具包,用于從非結構化文本中無監督地學習文本隱層的主題向量表示,支持包括TF-IDF、LSA、LDA和Word2Vec在內的多種主題模型算法,并提供了諸如相似度計算、信息檢索等常用任務的API接口。gensim官網對于其中Word2Vec模型的介紹為里面提供了和Word2Vec相關的完整使用文檔。首先如果沒有gensim的話,使用pip即可安裝。
pipinstallgensim
另外,gensim僅提供了Word2Vec的模型實現,訓練詞向量的另一個必須條件是足夠大的文本語料。這里將要使用的是中文維基百科語料,已經整理成文本文件并放在網盤上,直接下載使用即可,提取密碼為kade。
下載之后,可以在SublimeText中打開并查看其內容,文件名和后綴名可以不用在意,因為SublimeText支持打開任意類型的文本文件。其中每一行是一條維基百科,即一項詞條對應的百科內容,并且已經完成了分詞處理。
以下代碼使用gensim提供的Word2Vec模型訓練并使用詞向量,主要包括加載包、訓練模型、保存模型、加載模型、使用模型等步驟。
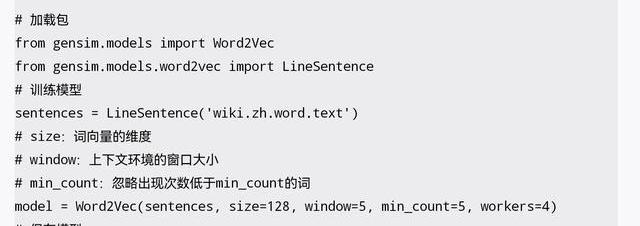

除此之外,gensim中的Word2Vec還實現了多項NLP功能,例如,從多個詞中找出和其他詞相關性相對更弱的一個,以及根據給定的3個詞類比推理出第4個詞等,詳細使用方法可以參考官方完整文檔。
人們總是無法停止對科技世界的探索。今年春晚,一群機器牛「拓荒者」登上舞臺;幾天前,雷軍在聲情并茂的演講中推出了Cyberdog「鐵蛋」;將視線移至天空之外,馬斯克一直鐘情于SpaceX的載人登月.
1900/1/1 0:00:00近期,加密行業乃至“圈外”對于元宇宙的討論越來越多,全民熱議的背后必定少不了其獨到之處。相比于“宇宙”,大家更多不理解的是添加“元”所蘊含的意義是什么.
1900/1/1 0:00:00中新社北京7月6日電 作者劉文文 最近數字貨幣又一次站在了風口浪尖。一邊是西班牙興致勃勃稱要加入創建數字貨幣的熱潮,另一邊美聯儲官員卻對數字貨幣褒貶不一……隨著區塊鏈技術的發展和賦能,全球掀起創.
1900/1/1 0:00:00廣東新增本土新冠確診病例4例據廣東省衛生健康委員會6月7日的消息,6月6日0至24時,廣東省新增4例本土確診病例,廣州報告3例,深圳報告1例;另有本土無癥狀感染者轉確診病例1例,廣州報告.
1900/1/1 0:00:00導語:肯德基其實是外國傳來的一種價格偏高的小吃,時至今日我們才發現,這種小吃在國外,確實也只能算得上是小吃罷了.
1900/1/1 0:00:00魔法科技每天給你帶來最新相關資訊——PHA動態、PHA官方資訊信息pha插槽拍賣結束即開啟頭礦,經濟模型清晰,頭礦收益率高,回本周期快,下半年第一個良心礦!大家不妨來了解一下.
1900/1/1 0:00:00


